
A blog covering the role-profile pattern across IaC and the why’s of Terragrunt
Back in the midst of time the Role-Profiles pattern that PuppetLabs promoted saved many a complex deployment. It was a way of using the configuration tool Puppet, that:
And it’s great to bring some of this to the world of Terraform and Kubernetes provisioning.
If you’ve worked on Terraform in more than one company you’ll likely have seen very different approaches to folder structure, module usage, and environment promotion. At CTS we’ve attempted to formalise our approach to infrastructure-as-code (IaC) somewhat based on the Role-Profile pattern. We’ve found that the Role-Profile pattern is a useful conceptual model that works across not only configuration (Puppet), but also resource provisioning (Terraform + Terragrunt), and application layer deployments in Kubernetes (Kustomize).
There’s an excellent slide-deck by Craig Dunn of Puppet Labs detailing the design of the Role-Profile pattern here:
In the stack diagram below, Roles, Profiles and Components are all written in the Puppet DSL.
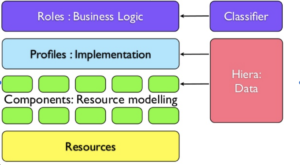
In summary:
If you don’t know Puppet, then it’s enough to know that there’s a system (node classifier) that maps Nodes (aka machines or VMs) to Roles.
For example, a machine may be assigned a UAT Server role by the Node Classifier and have the following profiles:
Picking the webapp profile it may have the following components:
Finally Puppet used another tool called Hiera to separate out the customisation of each of the layers.
Puppet also made some strong recommendations about how Hiera should be used in the Roles-Profiles method. See the rules section here:
The rules are of interest as they encapsulate best-practice that helps ensure that profiles and components are composable and reusable.
The rules distil down to:
These rules will guide us how and where Terraform with the Role-Profile pattern should be configured. Let’s take a look at how we can apply the pattern to Terraform.
If you have not used Terragrunt before it solves some Terraform issues (and introduces some of its own). At CTS, with hundreds of Terraform deploys a day across multiple customers, we are very interested in reducing the blast-radius of failed Terraform runs.
Typically, as soon as this becomes a problem for a company with a sufficiently complex infrastructure the easiest thing to do is separate the code base into multiple Terraform runs. Perhaps organised like so:
Now the decoupling means that when you update say your application you can in no way risk your network layer — however it does come with problems:
Perhaps you’ll write bespoke scripts to maintain the ordering? But there’s still no real dependency management. Over the course of time what’s stopping you from introducing cyclic dependencies between layers? Perhaps you’ll use TF state or data sources in order to discover data between the layers, but this is ad hoc and adds lots of code that was not needed before.
Luckily, Terragrunt solves a lot of these problems in a consistent manner. The Terragrunt docs themselves do a great job in explaining the motivations and features.
See:
And for an example of how Terragrunt is to be used
Here is typical Terraform/Terragrunt setup within CTS.
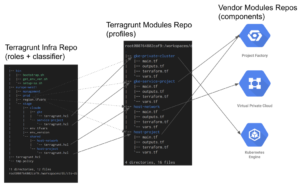
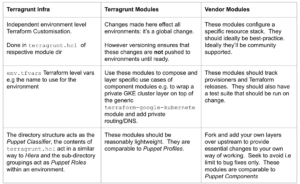
The following table shows how the 3 layers of repo map to the Role-Profiles pattern and how they should ideally be used.
Starting at the left of the example above, in the Terragrunt Infra Repo we have the cloudm directory in the staging environment of the europe-west-2 region.
This cloudm directory can be thought of as a Puppet role: it’s the infrastructure required to host one of CTS’ products. It requires a GCP Project and a GKE cluster. This is defined by the sub-directories gke and service-project and the configuration terragrunt.hcl within each.
Unlike Puppet and Hiera, the role configuration is not decoupled. Nor is it a formally defined entity i.e, to copy the cloudm role to prod you effectively copy the directory and configure the hcl with appropriate values. However, it is still a significant improvement – there’s no explicit Terraform resources in this layer.
note: it would be great to extend Terragrunt to support these notions properly.
Next we have the Terragrunt Modules layer — if we take the gke-private-cluster module as an example, it wraps the terraform-google-kubernetes module and in this particular case adds some routing and DNS. In more complicated modules, multiple vendor modules may be called. It is here we ensure solid common settings and capture how CTS thinks one should best call the various vendor-supplied modules across all environments.
Finally there’s the Vendor Modules — these are from the likes of Google who provide best practice modules as part of the Foundation programme. They can be taken from GitHub or the Terraform Registry. They compare almost directly with Puppet components — which are typically modules taken from Puppet Forge.
One can’t write about Terragrunt and not espouse the virtues of immutable versioned deploys. At the Terragrunt module repo layer we are able to make changes across multiple modules and use a git tag at the repo level to fix that code base in time. We specify that tag in the env_version file in each of the environments specified in the infra-live layer (see it in stage hierarchy above). Every terragrunt.hcl file uses that tag when it links to the profile to use. Now we can make changes to multiple modules and roll out in one step to dev. If it all goes well we can then bump the stage env_version file to the same tag for a very easy promotion that we know has been tested to work.
One final thing to mention is that we use Atlantis to monitor the Terragrunt Infra repo and plan automatically on pull-request. It’s configured to run Terragrunt at the profile level only. It sort of takes on the role of Puppet Master (or even ArgoCD in the K8s world — another abstraction to perhaps explore)
The Role-Profile + Component pattern fits well with Terragrunt and Terraform. The Terragrunt-Infra to Role is the weakest of the mappings in the pattern at present. However in its combined role of configuration, role definition and classifier it works well enough. The profile and component mappings are clear and obvious.
CTS has used this very successfully to:
We’ve also extended this pattern to our Kubernetes deploys with Kustomize and ArgoCD — but that’s for another blog post!
I’ve recently been made aware of the following patterns post by OpenCredo
The final pattern named TerraServices looks, at first glance, to map onto profiles (Infra-Module layer). OpenCredo refers to them as isolated logical components.
OpenCredo goes on to further talk about Orchestrating Terraform as all the isolated states require significant coordination. Hopefully I’ve shown that Terragrunt is a great solution to this — it’s open-source, it solves dependencies and it provides a common way of sharing data between the isolated runs.

CTS Team Google Cloud Next 2022 Highlights

How real-time data can improve government services
